Method
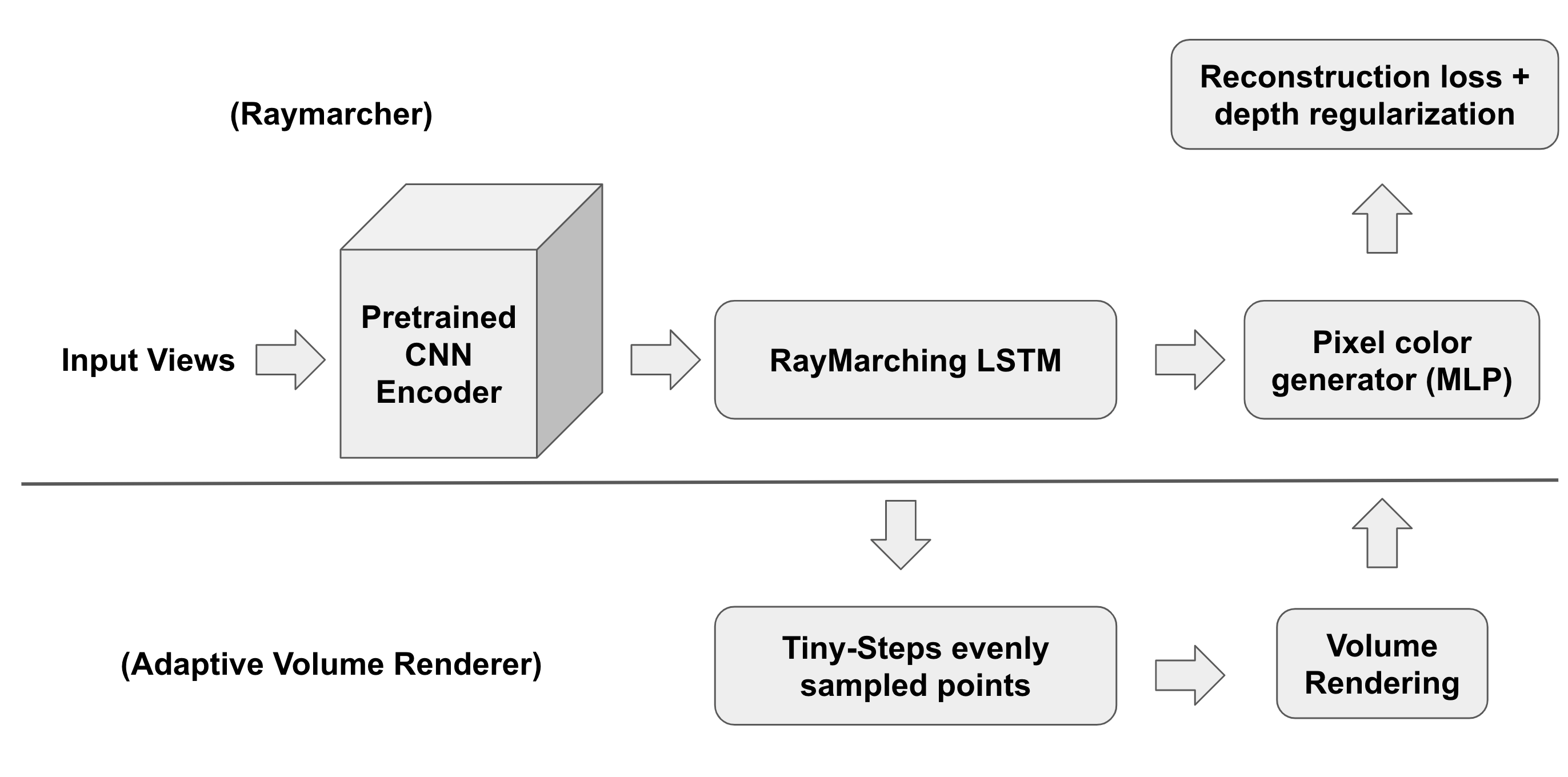
We propose an adapted version of differentiable ray marching algorithm that will first use ray marching long short-term memory (RM-LSTM) along the query ray to learn the adaptive step-length for the tracing algorithm. The goal of the RM-LSTM algorithm is to land in a neighborhood to the actual surface of the scene in order for the neural radiance field to learn the output. As this point, we can either directly output a color or, as a better alternative, sample points around the terminal point predicted by the RM-LSTM algorithm with much smaller step sizes and perform volume rendering along those points.
We did our experiment by modifying the current structure of PixelNeRF. Instead of a standard volume rendering procedure, we extract the latent features learned by the CNN encoder of PixelNeRF and then feed the features as input into the RM-LSTM algorithm in the picture below. Essentially, the RM-LSTM predicts the steplength on the ray of interest and update the depth. The RM-LSTM is set to have the number of feature channels being 512. We set the number of steps to be 10 in our experiments due to computational constraints. We then pass the output through the whole PixelNeRF network again to obtain rgb values. In order to guide the initial convergence process of LSTM, we add a regularization term to the usual MSE reconstruction loss by penalizing any final depth outside 0.5 (near plane) and 2.0 (far plane). In our experiments, we use pretrained ResNet 34 model for the CNN encoder. We denote this structure as Raymarcher.
For our extension, we did the same procedure as before up to the point where LSTM outputs the final depth. Now instead of extracting rgb values from PixelNeRF on this single point, we sample n = 10 points around +/-0.05 neighborhood of predicted depth and use standard volume rendering process to calculate the final rgb value. We denote this structure as AdaptiveVolumeRenderer (AVR).